June 2026
Teaching speech recognition to understand dysarthric speech (Part 1)
TL;DR. My goal with this project is to build an app that translates slurred (or atypical) speech of people with dysarthria into clear, understandable speech, ideally in their own voice when a sample of it exists. The foundation for that is a model that can actually understand dysarthric speech in the first place, and that turns out to be the hard part: today's best speech recognition models fail badly on severe dysarthria (55-65% of words wrong). This post is Part 1 of a research log on fixing that. The early win from Week 1: personalizing the model to one person's voice roughly halves the error. It's not enough on its own yet, and the main thing standing in the way is more data. Okay, now that you have some context, let's get into the post!
Introduction
So I've been at a bit of a crossroads lately. I've really wanted to challenge myself by working on something I deeply care about and that is technically hard, because hard problems are genuinely fun for me. I mean, that's one of the main reasons I loved programming. There was a time, say before 2023, when pure engineering scratched that itch. It was challenging and fun to learn systems, build things from scratch, and spend hours working on fixing a single bug. But nowadays I mostly just have Claude do that for me. (This post isn't about the pros and cons of AI-assisted coding, in case you're wondering. I'm heavily in favor of all of these tools anyway.)
However, with this new technological shift that we are in, it has pushed me to look elsewhere for interesting problems to work on. And one area that has been close to my heart for a long time is the brain, specifically neurodevelopmental disorders and motor disorders. Since I was a kid I'd read memoirs from people with autism or an intellectual disability and try to see the world through their eyes, or dig deep into speech-language pathology. I was always a little too afraid to go knee-deep into these fields. I figured they were too hard and that I probably wouldn't make much progress, so I stayed away and focused on building a ton of software projects (like PoolShark and Joygram, both of which I'm really proud of; 10+ people make a Joygram every single day with literally no marketing, which is amazing!).
But after thinking hard about what I want to do with my life, the thing I keep coming back to is this: being able to do, or eventually build a lab around, core brain research, from neuroscience, cognitive science, and genetics angles, working toward cures for genetic neurodevelopmental disorders like Fragile X Syndrome, and building assistive technology for people living with these conditions today. That would be an absolute dream for me, and I think it's a field that needs more serious progress.
So given that, I finally started getting back into this journey and going knee-deep. And of course, why not also blog and share my learnings and progress along the way!
What is dysarthria?
One of the first motor-speech disorders I came across was dysarthria. Dysarthria is a speech disorder that can result in slurred, slow, or hard-to-understand speech. It happens when the muscles involved in speaking are weakened or harder to control. It's commonly seen in people with ALS, and it also shows up with cerebral palsy, Parkinson's, multiple sclerosis, and after a stroke.
It's more common than you'd think. A figure of around 0.8% of the population is cited in the TORGO database paper. If we assume that to be right, that's approximately 5 million people in North America alone.
For many people with dysarthria, speaking takes a lot of effort, and it's exhausting to have to repeat yourself over and over and still not feel fully understood or heard. That's a real problem, because at the moment, voice is our primary medium of communication (give it a few years and we might all be communicating telepathically with Neuralink haha).
Coming from a largely AI and engineering background, I started looking into the solutions that exist today, and the options are surprisingly limited. In this video, an individual with dysarthria describes how a lot of current tools don't really work well for slurred speech. They end up repeating commands to their devices again and again, to the point where the tools are more work and more exhausting than they are helpful.
I mean, just think about voice assistants or live captioning. The modern ASR (automatic speech recognition) models that power those tools aren't well suited to atypical or slurred speech. They often produce empty or hallucinated transcripts.
So how bad are the current ASR models at recognizing slurred speech?
I grabbed Whisper large-v3, one of the state-of-the-art ASR models, and found the TORGO dataset, a freely available dataset of recordings from speakers with cerebral palsy or ALS. I ran Whisper on it with no fine-tuning, just to see where things stand.
The metric here is WER (word error rate): the percentage of words the model gets wrong (lower is better). As a rough rule of thumb, you want to be under ~10% for a transcript to be reliable enough to actually depend on.
Here's the zero-shot picture across speakers, grouped by how severe their dysarthria is:
| severity | zero-shot WER |
|---|---|
| very mild | 1-2% |
| mild | ~10% |
| moderate | 25-44% |
| severe | 55-65% |
So the model is basically perfect on the mildest speakers and basically unusable on the severe ones (more than half the words wrong). So this prompted me to try to fix it. :)
What I tried in Week 1 (June 14 to 19)
With that baseline in hand, the obvious question was: can I fine-tune a model to close the gap? Here is what I tried, roughly in order, and what actually worked.
So the first thing is you need to be careful with using the TORGO dataset. TORGO reuses the same ~957 sentences across speakers, so if you're not careful the same sentence ends up in both training and testing, and the model just memorizes the transcript. That can make results look ~10x better than reality. Every number below uses splits that are disjoint by speaker and by sentence, and because the test sets are small, I average every result over 3 random seeds. It's not ideal, but it's the best I can do at the moment given I don't have access to the Speech Accessibility Project (SAP) dataset yet (I've requested access, so hopefully it works out!).
Attempt 1: one model for everyone (generic fine-tuning)
The first thing to try is the obvious one: take all the other dysarthric speakers, fine-tune on them, and test on a new, held-out speaker. (I used LoRA, a lightweight fine-tuning method that trains a small "adapter" and leaves the base model frozen.) The question this answers is: can a single model learn "dysarthric speech in general" and generalize to a new person?
The honest answer was not really. On average it barely moved the needle, and the average hides a lot:
- It helped the moderate speakers a bit.
- The severe speakers, the ones I actually care about, barely budged.
- The mild speakers actually got worse, because a generic "dysarthric" adapter drags near-typical speech toward some average dysarthric distribution.
This kind of implies there is no single "dysarthric model." Severe dysarthria is highly individual, and one model can't fit everyone at once.
Attempt 2: personalize to one person (the win)
So if "one model for everyone" doesn't work, what about the opposite? Train a tiny adapter on one person's own voice and use it just for them. Each person reads a small number of sentences (think of it like a short enrollment), I train a small adapter on those, and then test on different sentences from the same person.
This is where it got exciting. Every hard speaker improved a lot.
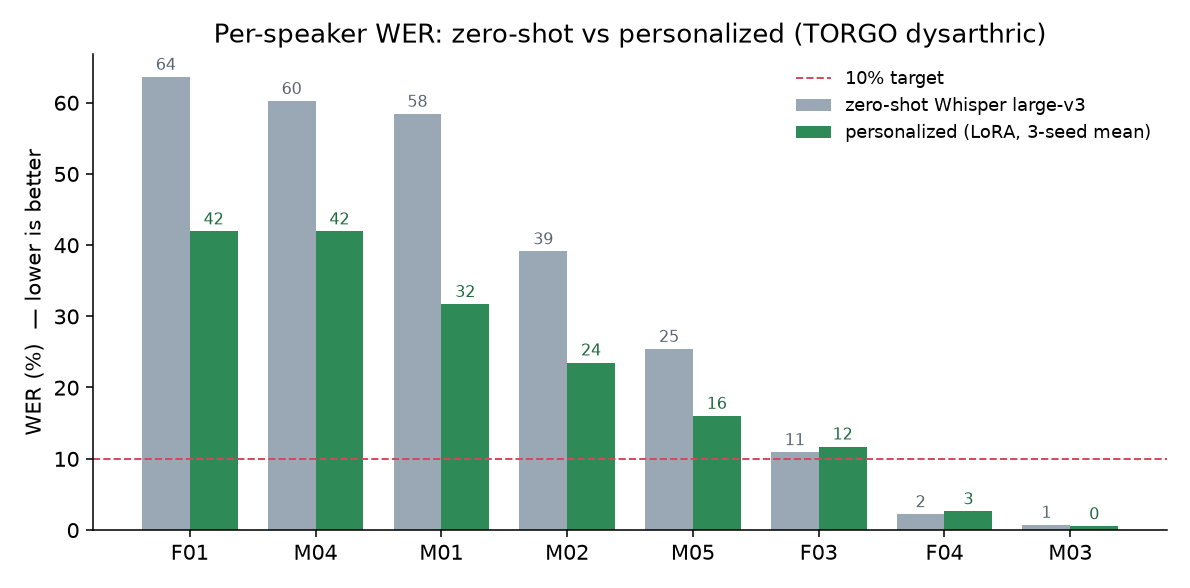
| speaker | zero-shot | personalized |
|---|---|---|
| M01 | 58.4 | 31.7 |
| F01 | 63.6 | 41.9 |
| M04 | 60.2 | 41.9 |
| M02 | 39.1 | 23.5 |
| M05 | 25.4 | 16.0 |
Personalizing roughly halved the error for the severe speakers, about 3x the gain I got from the generic approach.
However, none of the speakers are under 10% (excluding the mild speakers, which are already solved by the baseline Whisper model). Personalization clearly helps, but on its own it isn't enough for the most severe cases. And it's noisy for them: F01, the most severe speaker, has only ~20 clips of usable data total, so it's genuinely starved for data. That actually mirrors the real-world constraint, where a severe speaker would need to record more before the system can adapt well.
Attempt 3: teach it dysarthria first, then personalize (the honest miss)
So I started reading papers from others who have made progress in this field. One in particular, introducing the CBA-Whisper model, has been very helpful.
I need more data for each personalized speaker, but I can only work off of TORGO for now, so I decided to try a 2-step fine-tuning process:
- First adapt the model to "the domain" (dysarthria in general).
- Then personalize the individual on top of that fine-tuned model.
So basically, the goal is to first build a "dysarthria-aware" base by fine-tuning on the other speakers, then personalize on the target.
Sadly, with just the TORGO and UA-Speech datasets, it made things a bit worse, on every variation I tried.
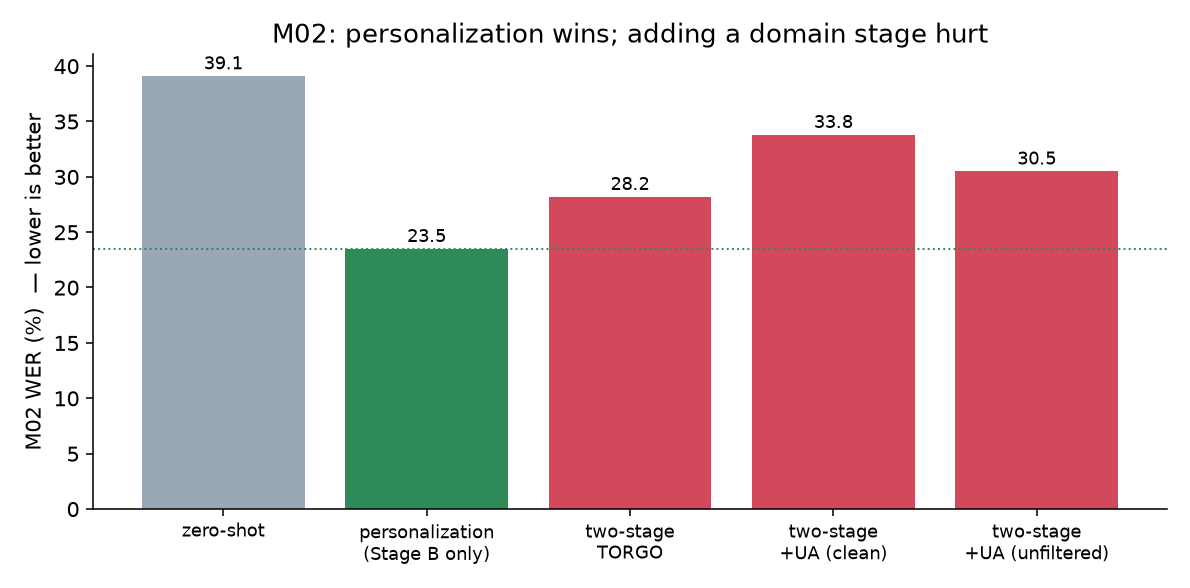
| approach (speaker M02) | WER |
|---|---|
| personalization only | 23.5 |
| + domain stage (TORGO) | 28.2 |
| + domain stage (TORGO + UA-Speech) | 30-34 |
Based on these results, I'm still convinced scale is the lever, but unfortunately it's tough for me at the moment since I'm waiting on access to the SAP dataset. A "domain" of only 6 speakers is too thin. Adapting to it nudges the base model in a direction that doesn't fit the target person, and a handful of their clips can't pull it back.
Also, UA-Speech is single words, not sentences. Mixing a pile of single-word clips into the training set skewed things, and the audio just didn't transfer well to recognizing connected speech.
To summarize where I'm at after Week 1
| approach | best result (M02) | verdict |
|---|---|---|
| zero-shot | ~39-45 | unusable |
| one model for everyone | ~38 | weak, hurts mild speakers |
| personalize to the person | 23.5 | best so far, halves the error |
| domain stage + personalize | 28-34 | worse, domain too thin |
What's next
The big unlock is large-scale, sentence-level clinical data. The Speech Accessibility Project (SAP) has recordings from hundreds of speakers across many conditions, which is exactly the kind of corpus the domain stage needs. I've submitted a request and hopefully should hear back in the coming weeks!
In the meantime, I'm reaching out to and connecting with speech-language pathologists (SLPs) who work with people who have dysarthria and other motor-speech disorders. I want to learn from the people who do this day to day: what matters most to their patients, where the existing tools fall short, and what "good enough" actually looks like in practice. I'll also keep pushing on the technical side, squeezing more out of personalization (like augmenting each speaker's enrollment data) and tightening up the evaluation so the per-speaker numbers are more trustworthy.
This is genuinely a fascinating problem, and this is just Part 1 of the log, synthesizing my first week. More soon.